.webp)

Executive Summary
- Physical and digital documents are used everywhere, and they play a key role in connecting many business processes.
- Most unstructured information is locked in documents.
- Document processing technology has been advancing through six generations—from optical character recognition to ecosystem information management.
- The latest generation, cognitive document processing, uses cognitive AI (the fusing of visual AI’s perception, predictive AI’s forecasting, and agentic AI’s reasoning/acting, to understand context and data element relationships to extract information from documents, and handle variability with zero-shot setup
- Adopting advanced document processing improves business outcomes including adaptability, transparency/auditability, and lower maintenance costs
- Understanding the evolution of document processing technologies provides a useful foundation to develop document processing strategies.
Introduction
Documents are fundamental to almost all business and governmental operations. They are used to encapsulate information, convey instructions, and record transactions. Document processing involves extracting their content, understanding their meaning and significance, and transferring their information to business systems.
Documents can be physical and digital, and there are a lot of them. For example, on the physical side, the global trade sector alone creates approximately 4 billion paper documents a day. On the digital side, it is estimated that there are more that 2.5 trillion PDF documents in the world.
In 2025 it is forecasted that we will generate 181 zettabytes of new data and 80% to 90% of that will be unstructured. Considering the massive volume of documents and their critical importance to the functioning of business processes, it is not surprising that businesses and governments have invested huge effort to digitize and automate document handling and processing.
The Evolution of Document Processing
Until the late 1980s, documents were processed entirely by people. Humans are highly adept at interpreting documents, improving with experience and requiring little formal training to adapt to new document types. They are flexible and capable of handling significant variability. However, people are also expensive resources, and their output, both in quality and throughput, can vary widely. Moreover, the volume of documents eventually exceeded the capacity of manual workforces to keep pace. With the rise of computers and the internet, organizations turned to technology to digitize documents and manage them at scale more efficiently and affordably.
Over the past thirty years, document processing has advanced through several waves of innovation. These include breakthroughs in optical character recognition (OCR), the introduction of machine learning for more accurate classification, and the integration of natural language processing (NLP) to enhance data extraction. Each generation has built on the strengths of the last, evolving document processing from keyboard-driven digital transcription into a fully automated and integrated component of complex business processes.
Today, document processing is a core enabler of digital transformation. It accelerates the handling of critical business information, reduces costs, increases automation, and enhances decision-making. Organizations now recognize that documents; whether paper or electronic, structured, semi-structured, or unstructured; contain vital business intelligence. When captured, organized, and understood, this information becomes a powerful business asset. Recent advances in underlying technologies have made the return on investment from document processing more compelling than ever.
This paper examines the evolution of the five most recent generations of document processing technologies: OCR, robotic process automation (RPA) document processing, intelligent document processing (IDP), generative pretrained transformer (GPT)/large language model (LLM) document processing, and cognitive document processing (CDP). It also looks ahead to the potential emergence of ecosystem information management (EIM). We will explore the technologies behind each generation, how they integrate with and complement process automation systems, their respective strengths and limitations, and real-world use cases that demonstrate their business value.
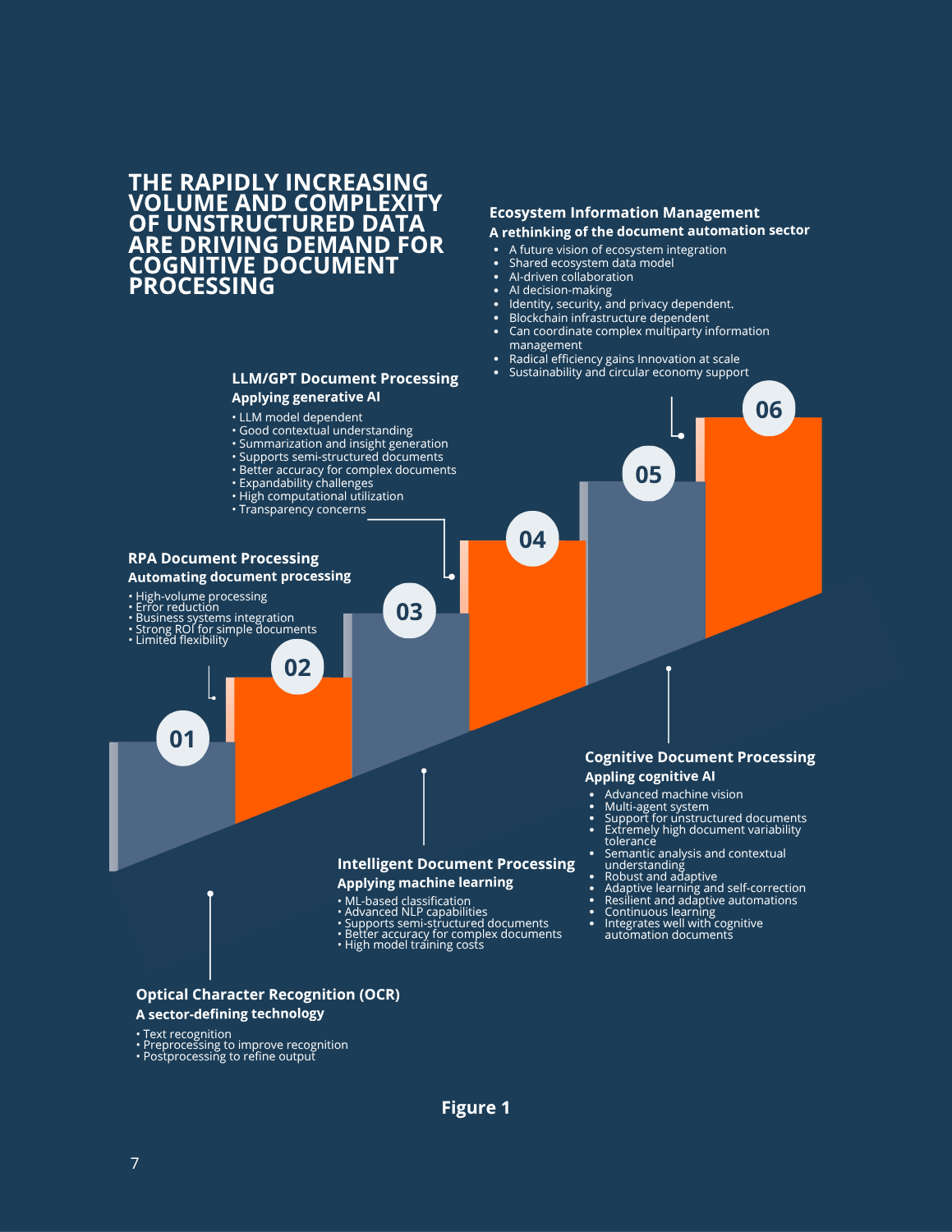
Generation 1: OCR
Optical Character Recognition (OCR) detects characters in document images by analyzing their shapes, converting them into machine-readable text that can be used in digital systems.
Preprocessing
After a document is captured, preprocessing techniques, such as noise removal, de-skewing (straightening tilted text), and binarization (converting to black and white), are applied to enhance clarity and improve recognition accuracy.
Postprocessing
Once characters are recognized, postprocessing methods like spell-checking, dictionary-based corrections, and natural language processing (NLP) are used to refine the output and correct errors.
Strengths
Traditional OCR performs well on clean, printed text in standard fonts. Although it struggles with noisy or unstructured documents, OCR still marked a major leap in efficiency, enabling faster document processing, improved searchability, and significant cost reduction compared to manual methods.
Limitations
OCR is far less effective for semi-structured, unstructured, or handwritten text. As a result, its standalone utility is limited in many real-world document processing scenarios without the support of complementary technologies.
Key Characteristics of OCR
- Text recognition: Converts printed or handwritten text into machine-readable formats.
- Image preprocessing: Enhances input quality through techniques such as noise reduction, de-skewing, and binarization.
- Pattern and feature recognition: Identifies characters and symbols based on their shapes and structures.
- Language and font versatility: Supports multiple languages, character sets, and font styles.
- Flexible output formats: Delivers results in formats such as plain text, searchable PDFs, or structured data.
- High scalability: Processes large document volumes efficiently across industries.
- Pre- and postprocessing support: Incorporates spell-checking, dictionary corrections, NLP, and other refinements to improve accuracy.
Example Use Cases for OCR:
DOCUMENT DIGITIZATION FOR ARCHIVING
An insurance company uses OCR to convert physical documents, such as manuals, contracts, and records, into digital formats. This reduces reliance on physical storage while making critical information more searchable and accessible across the organization.

AUTOMATED DATA ENTRY FROM FORMS
A shipping company applies OCR to extract text automatically from structured forms, including invoices, receipts, and applications. This automation eliminates manual data entry, saving time, reducing errors, and improving operational efficiency.
As revolutionary as OCR was, it has always been limited. Over time, the technology has been enhanced with complementary tools to improve both its accuracy and practical usefulness. The next major step in document processing came with its integration into robotic process automation (RPA).
Generation 2: Robotic Process Automation Document Processing
The digitization of documents is not only a standalone process but also a critical part of broader business workflows. RPA offered an efficient way to streamline these workflows, and as a result, OCR and RPA have become closely linked and are often packaged together.
Repetitive Task Automation
RPA document processing excels at automating repetitive tasks such as invoice processing and patient data management. It uses OCR to read, interpret, transform, and classify documents, while “automations” or “bots” load the extracted data into databases and enterprise resource planning (ERP) systems for use in downstream processes. Because it relies on rule-based logic and predefined templates, RPA is well suited for handling large volumes of structured documents in predictable formats.
Strengths
RPA document processing is highly effective at digitizing simple, structured documents. It enables organizations to process documents at scale with low costs and high quality, reduces human error, and allows staff to be redeployed to higher-value tasks. Compared with more advanced AI-driven systems, RPA also requires lower upfront investment and has a lower overall cost of ownership, making it an attractive choice for straightforward use cases.
Limitations
RPA document processing is restricted to simple, structured, and non-variable documents that conform to fixed formats. In practice, most organizations also deal with large volumes of complex, unstructured, or variable documents that RPA cannot handle effectively. Because RPA depends on static rules and templates, it lacks adaptability and requires constant maintenance when document formats change.
Some organizations have managed to extend RPA to moderately complex documents through extensive coding, customization, and exception handling. However, these solutions remain fragile and still lack adaptability. RPA is further limited by its inability to interpret the meaning and relationships between data elements or to understand broader document context. As a result, its utility is confined to basic data extraction, which restricts the overall business value of the information it captures.
Key Characteristics:
- Extends OCR capabilities: Builds on OCR to automate data extraction and entry.
- Optimized for structured documents: Well-suited for high-volume, predictable formats such as invoices or forms.
- Strong ROI for simple automations: Delivers cost savings and efficiency in repetitive, rules-based tasks.
- Error reduction: Minimizes human transcription errors by automating data handling.
- Broad system integration: Connects with a wide range of enterprise platforms and applications.
- Limited flexibility: Struggles with variability, semi-structured, or unstructured documents.
- Lacks contextual understanding: Cannot interpret meaning or relationships beyond predefined rules.
Example Use Cases for RPA Document Processing:

INVOICE PROCESSING
A finance department uses RPA document processing to extract invoice data, vendor details, and payment terms. An RPA bot then transfers the extracted data into the organization’s accounting system for approval. This automation reduces manual effort, improves efficiency, and accelerates payment cycles.

FORMS PROCESSING
A healthcare provider applies RPA document processing to scan and extract patient information from structured admission forms. An RPA bot transfers the data into the patient management system, reducing administrative errors and shortening wait times. Automating this process enhances the overall patient experience while improving operational efficiency.
RPA document processing was the norm until the mid-2010s when AI technologies started to add comprehension capabilities to document processing.
Generation 3: Intelligent Document Processing
Intelligent Document Processing (IDP) extends RPA document processing with machine learning technologies such as deep learning, neural networks, machine vision, and natural language processing (NLP). These advancements revolutionized how digital text, handwriting, and image-based data are handled, enabling IDP systems to classify documents and extract key information from both structured and semi-structured formats. IDP is significantly more capable of managing different versions of the same document type, including complex invoices, purchase orders, and emails: making document processing more valuable to organizations.
Classification
By leveraging machine learning’s ability to recognize patterns, IDP provides far more advanced classification capabilities than earlier generations. As a result, information can be routed automatically with minimal human input. For example, IDP can categorize incoming documents such as invoices or contracts and forward them directly to the appropriate department. This reduces manual intervention and makes it easier to integrate document content into complex business processes.
Data Extraction and Interpretation
Beyond classification, IDP excels at extracting and interpreting document content. With the support of machine learning and NLP, it can analyze and accurately capture key data elements such as names, dates, places, and amounts, providing richer insights for downstream systems.
Limitations
Despite its strengths, IDP depends heavily on training with large volumes of labeled, domain-specific documents (≈2,000 for semi-structured and ≈10,000 for unstructured). This makes IDP expensive to set up and maintain. Its accuracy is strongly tied to the quality and scope of the training set, and performance declines when documents fall outside expected norms. Many vendors also publish misleading accuracy figures that only reflect results within a narrow set of document types.
Contextual Understanding
While IDP is more capable than RPA at interpreting documents, its ability to understand data context and relationships between data elements remains limited. This restricts its usefulness in scenarios requiring informed decision-making or high levels of data accuracy in business processes.
Applicability
IDP introduces significant new capabilities but struggles with highly variable or unstructured documents, which limits its effectiveness in complex environments. The integration of machine learning and advanced NLP has raised accuracy to as high as 95%, but only for the subset of documents the system has been trained on. In many organizations, these documents represent only about 25% of the total incoming volume, leaving roughly 75% still requiring human-in-the-loop intervention.
Key Characteristics of Intelligent Document Processing (IDP):
- Machine learning–driven classification and extraction: Identifies document types and extracts key fields with greater intelligence than rule-based system.
- Enhanced OCR accuracy: Provides more reliable text recognition compared to traditional OCR.
- Advanced NLP capabilities: Interprets context, entities, and relationships within documents.
- Support for semi-structured documents: Handles formats such as invoices, purchase orders, and forms with variable layouts.
- Reduced human intervention: Requires human-in-the-loop validation for fewer documents.
- Template dependence: Performance often tied to the quality and relevance of templates.
- High development and maintenance costs: Model training and upkeep demand significant time, data, and resources.
- Limited scalability for complex processes: Struggles to extend beyond semi-structured tasks or highly variable documents.
Example Use Cases for IDP:

INSURANCE CLAIM PROCESSING
An insurance company uses IDP to process claim forms, classifying documents, extracting key data such as policy numbers and claim amounts, and passing that information to a business process. This improves response times and reduces costs.

EMAIL PROCESSING
A customer service department uses IDP to classify incoming emails based on content and automatically routes them to the correct team (e.g., billing inquiries, support requests). This reduces response times and improves customer satisfaction by ensuring emails are directed appropriately and efficiently.
IDP’s use of machine learning and deep learning enables it to handle a much wider variety of documents. Its ability to interpret different data types significantly improves classification and makes information more valuable to businesses. However, organizations increasingly require more advanced systems that leverage perception-first, zero-shot extraction.
Generation 4: GPT/LLM Document Processing
Document processing advanced significantly with the advent of transformer-based AI. Generative Pretrained Transformers (GPTs) and large language models (LLMs) introduced deeper contextual understanding, making it easier to extract insights from unstructured text.
Understanding
GPT/LLMs are particularly valuable in the downstream information-processing stages of document workflows. Once documents are ingested, they can interpret both context and content, streamlining tasks that previously required extensive manual effort, such as analyzing complex contracts, identifying key clauses, and generating summaries within seconds. Their ability to understand context across multiple languages and domains makes them versatile tools for industries operating in diverse geographies.
Limitations
Although the contextual insights generated by GPT/LLMs are highly valuable, the way these models reach their conclusions can be problematic. Unlike traditional models, which can trace outputs back to specific rules or weights, GPT/LLMs operate largely as black boxes. This lack of transparency makes it difficult to verify their reasoning or assess potential biases and hallucinations. Recent research has even questioned the authenticity of the “chain of thought” reasoning these models provide as an explanation for their decision-making. Such challenges are especially concerning in sensitive domains such as legal or healthcare document processing, where errors can have serious consequences. Explainability concerns are further compounded by context blindness to layout and visual cues, as well as the risk of error amplification when reasoning over poorly structured inputs.
Costs
Deploying GPT/LLMs for document processing often requires fine-tuning for specific industries and tasks. This process is expensive and time-consuming, requiring domain expertise and large volumes of labeled training data. In addition, these models demand significant computational resources at inference (runtime), making large-scale deployments costly. As a result, GPT/LLM-based document processing is powerful but not a one-size-fits-all solution.
Key Characteristics of GPT/LLM Document Processing:
- Contextual understanding: Interprets meaning beyond keywords, capturing nuance and intent in documents.
- Multilingual capability: Processes and analyzes content across multiple languages with high accuracy.
- Domain adaptability: Applies knowledge flexibly across industries and subject areas without retraining for every use case.
- Summarization and insight generation: Produces concise overviews, extracts key points, and identifies patterns within large text sets.
- Strength in unstructured data: Excels at handling unstructured and semi-structured documents, such as emails, contracts, and reports.
- Explainability challenges: Functions as a “black box,” making it difficult to trace reasoning or validate outputs.High computational demand: Requires substantial resources for training and inference, driving up operational costs.
Example Use Cases for GPT/LLM Document Processing:

MORTGAGE APPLICATIONS
A financial services company leverages LLM/GPT document processing to extract critical information, such as income, assets, and liabilities, from lengthy mortgage applications. This automation streamlines a traditionally time-consuming step in the home-buying process, reducing bottlenecks and accelerating approvals.

IMPROVED PATIENT OUTCOMES
A hospital applies LLM/GPT document processing to analyze clinical notes, extract key patient data, and even suggest preliminary diagnoses from patient records. This improves the use of hospital resources and enables patients to receive better care, faster.
While GPT/LLM-based document processing can be costly and is not a one-size-fits-all solution, their blend of contextual understanding and adaptability makes them powerful tools for automating and optimizing document workflows. A practical way to mitigate LLM limitations is to combine them with visual AI, which structures and contextualizes inputs before LLM reasoning is applied.
Generation 5: Cognitive Document Processing
CDP is a new technology that extends the capabilities of previous generations of document processing, enabling it to handle a broader range of documents. It leverages Cognitive AI, which integrates visual AI for perception, predictive AI for forecasting, and agentic AI for reasoning and tool use. This combination allows CDP to extract, normalize, and contextualize information in a zero-shot manner, requiring no training.
Perception Foundation: Why Visual AI First?
Before reasoning or orchestration, automation must first perceive what is in front of it. Visual AI creates a structured understanding of documents and application screens by capturing text, layout, tables, labels, and context. As a result, downstream components receive clean, well-typed inputs instead of raw pixels or brittle templates. This perception-first layer stabilizes automation as formats, UIs, and policies change, reduces maintenance costs, and transforms previously “too variable” work into repeatable inputs for predictive and agentic steps.
- Semantic + spatial map, zero-shot: Visual AI constructs a semantic–spatial model of documents and UIs (including VDI and remote apps), tolerates novel layouts and languages, and enables zero-shot extraction without per-variant templates.
- Better inputs - safer reasoning: By structuring and validating inputs first, reasoning becomes cheaper and more accurate, with fewer hallucinations and less drift across policy or UI changes.
- Continuous learning: Multi-tool consensus (e.g., cross-model agreement, validators), combined with human-in-the-loop feedback, closes the loop. Parsers, thresholds, and playbooks are continuously updated as new variants appear.
The perception, contextualization, and understanding provided by visual technologies complement the reasoning and execution capabilities of agentic AI, delivering stronger results while consuming fewer computational resources. This approach mirrors how the human brain works: visual systems act as a cognitive pre-processor, applying element grouping, pattern recognition, and synthesis to integrate diverse information, context, and perspectives into a unified understanding. This filtered, contextualized information can then be passed to agentic systems for deeper analysis and reasoning. The result is not only higher-quality information capture but also information that is more actionable and valuable to organizations.
Zero-Shot Capability
Because of its cognitive preprocessing, CDP can extract high-quality data from documents in a zero-shot manner (without model training). This significantly reduces development, deployment, and runtime costs, accelerating time-to-value.
Why “Zero-Shot” Matters
Faster onboarding:
Instead of collecting templates and retraining for each format, zero-shot Visual AI adapts to novel layouts and virtual desktop infrastructure screens through configuration rather than training. This reduces SME bottlenecks and accelerates time-to-value from weeks to days, or even hours.
Reduced labeled-data burden:
Foundational perception minimizes or eliminates the need for large, per-variant labeled datasets. Learning instead comes from light guidance, validator rules, and human-in-the-loop feedback, expanding coverage while lowering data preparation and retraining costs.
Multi-System Analysis
CDP leverages multiple technologies including machine vision, advanced OCR, deep learning, advanced NLP, semantic analysis, large vision models, and vision–language models. These systems work together to provide comprehensive document analysis and understanding. To mitigate tool deficiencies and reduce the risks of model bias, CDP combines outputs through refinement, extraction, and best-result analysis. This enhanced contextual understanding enables CDP to extract information from unstructured documents, such as contracts, legal briefs, and research papers, with very high accuracy.
Contextual Metadata
The capture of context and relationship metadata improves extraction accuracy while also increasing the inherent value of the information. By enriching document content with contextual insights, CDP enhances decision-making and strengthens downstream business processes.
Self-Correcting
The multi-tool approach, combined with improved contextual understanding and recognition of relationships between data elements, creates a foundation for continuous learning. Over time, CDP systems can self-correct and adapt, becoming more flexible, maintainable, and effective at handling document variability and complexity.
Lower Costs
Once data is preprocessed, CDP can apply advanced techniques—including machine vision, fuzzy logic, vision–language models, LLMs, and other cognitive methods—to extract information. This cognitive systems approach allows CDP to process more complex documents at higher quality and lower cost than IDP or GPT/LLM-only solutions.
Key Characteristics of Cognitive Document Processing (CDP):
- Multi-tool architecture: Combines complementary tools and models to maximize accuracy and resilience.
- Deep learning OCR: Provides superior text recognition across varied fonts, formats, and quality levels.
- Advanced NLP and machine vision: Enables semantic analysis, entity recognition, and visual context interpretation.
- Large vision and vision-language models: Enhances cross-modal understanding of documents by linking visual and textual elements.
- Context-aware data extraction: Interprets information based on surrounding content and relationships.
- Semantic understanding: Goes beyond raw text capture to understand meaning, structure, and intent.
- Unstructured document handling: Processes variable, complex documents such as contracts, research papers, and legal briefs.
- Domain-aware validators: Applies domain-specific rules to refine accuracy and reduce errors.
- Reinforcement learning feedback loops: Continuously improves system performance by learning from outcomes and corrections.
- Tolerance for variability: Handles diverse document formats, policies, and layouts with ease.
- Flexibility and versatility: Adapts to a wide range of document types and business applications.
- Robust and resilient: Maintains performance despite changes in input quality or environment.
- Faster deployment, lower costs: Reduces development, training, and maintenance overhead.
- Improved data quality: Enhances accuracy, consistency, and reliability of extracted information.
Example Use Cases for CDP:

Contract analysis:
A legal department uses CDP to analyze complex contracts, automatically identifying key clauses, obligations, and risks. The system highlights areas that require review or negotiation, reducing the workload of legal teams and enabling them to focus on more strategic tasks.

Regulatory policy enforcement:
An energy company uses CDP to ensure compliance with environmental and safety regulations by automating the extraction and analysis of critical data from inspection reports, permits, drilling permits, environmental impact assessments, safety inspection reports, and emissions logs. The system extracts key data points, cross-reference the data with local and international regulatory standards and flags non-compliance issues or anomalies in real time.
CDP processes document much more like humans do. This gives cognitive process automation (CPA) systems that incorporate its abilities, human-like flexibility in workflows. CPA is the main way that CDP processed documents will be incorporated into business workflows.
CPA builds on the same perception foundation as CDP. It uses Visual AI to “understand before acting.” It then layers agentic planning and tool use to plan, act, and adapt across applications. Instead of brittle rules, CPA composes skills and policies to navigate changing UIs, tolerate vendor drift (including virtual desktop infrastructure), and recover from exceptions. An observer pattern learns from how humans resolve edge cases, so the system continuously reduces exception debt while improving speed, accuracy, and explainability.
- Loan underwriting: CDP normalizes paystubs, bank statements, IDs, and income proofs; CPA validates eligibility against policy, reconciles discrepancies, requests missing docs, updates the LOS/CRM via UI/API, and escalates only complex exceptions, shortening time-to-decision.
- Claims adjudication: CDP parses mixed packets (FNOL forms, adjuster notes, photos, invoices); CPA verifies coverage, detects potential fraud indicators, calculates payouts, enters decisions across carrier systems, and triggers payments or recovery workflows with full auditability.
- Supply-chain exceptions: CDP extracts data from invoices, bills of lading, labels, and carrier portals; CPA matches shipments to POs, replans routes or bookings, completes confirmations in third-party UIs, and notifies stakeholders, reducing dwell time and chargebacks.
The cost and flexibility advantages of this approach are likely to accelerate its adoption in processes and workflows that involve complexity and variability of documents.
Generation 6: Ecosystem Information Management
The future of document processing is likely to evolve into Ecosystem Information Management (EIM). EIM extends CDP/CPA capabilities across firms through shared data and control planes, with blockchain-backed fabrics providing identity and provenance. This approach will seamlessly integrate AI-driven document processing into broader business ecosystems. Unlike earlier generations, which focused on departmental or use case–specific automation, EIM aims to create a fully interconnected environment that enhances collaboration and enables real-time decision-making across business networks.
Cross-Ecosystem Workflows
EIM will process documents in real time as part of end-to-end automated workflows spanning multiple systems and organizations. For example, an EIM platform could connect customer relationship management and compliance systems across companies to ensure that customer data is accurately processed and verified without manual intervention. These systems move beyond simply extracting data, they treat documents as components of an interconnected information ecosystem rather than isolated data sources. This perspective enables more comprehensive, ecosystem-wide decision-making.
Data Fabric
EIM relies on advanced cognitive and reasoning AI, real-time data sharing, agentic workflows, and interoperability via a shared data fabric, often supported by blockchain infrastructure. This enables organizations to operate in highly coordinated, efficient, and collaborative configurations. Blockchain services add essential identity and reputation mechanisms, giving participants confidence in both the authenticity of documents and the integrity of associated metadata.
Efficiency
EIM reduces manual input and duplication in workflows such as data entry and document verification. It manages documents and their embedded information as part of a broader, integrated process and can process and analyze documents in real time. By linking multiple businesses through shared systems, EIM eliminates silos and improves overall operational efficiency.
Challenges
While EIM promises radical efficiency gains and innovation at scale, it requires substantial investment in infrastructure, process redesign, and the development of interoperability standards and decentralized governance systems. Technical hurdles include integrating diverse systems, ensuring data compatibility across platforms, protecting data privacy, and coordinating among stakeholders with varying technological capabilities. In addition, EIM adoption demands a cultural shift, as businesses adapt to fully automated, real-time, multiparty operations.
Key Characteristics of Ecosystem Information Management (EIM):
- Holistic integration: Connects workflows and data across ecosystem partners for seamless collaboration.
- Shared data environment: Provides a trusted, unified platform for information exchange.
- Real-time document processing: Embeds automated document handling directly into business systems.
- Real-time analytics and decision support: Delivers instant insights to guide operations and strategy.
- AI-driven decision-making: Applies advanced models to evaluate scenarios and recommend optimal actions.
- AI-to-AI collaboration: Enables autonomous agents from different organizations to coordinate and share insights.
- Interoperability: Integrates smoothly with multiple backend systems across the ecosystem.
- Ecosystem-wide efficiency: Enhances speed, accuracy, and productivity across interconnected enterprises.
- Security and privacy management: Ensures compliance, governance, and protection of sensitive information.
- Reliance on blockchain-based infrastructure: Depends on complex digital frameworks to enable trust, provenance, and decentralized governance.
Example Use Cases for EIM:

Procurement automation:
A multinational corporation with complex multiparty supply chains might use EIM to automate an entire procurement process, from receiving purchase orders to negotiating contracts, managing suppliers, and processing payments. This can significantly reduce procurement cycle times and minimize human errors, enhancing overall efficiency.

Legal compliance:
A financial institution facilitating trade finance might use EIM to automatically analyze and process regulatory documents across multiple jurisdictions, ensuring real-time compliance with changing legal requirements. This helps avoid penalties and improves audit readiness, providing greater operational assurance.
EIM and the associated ecosystem economy implies both a technical and a behavior complexity that will be very difficult to overcome. Like all technology and business change it won’t just appear it will evolve. We will likely see the technology, change management, and business cultural changes that are required to manifest inside of large companies and then inside of highly concentrated ecosystems. Eventually highly composable ecosystems will evolve that will leverage digital infrastructure that includes EIM functionality.
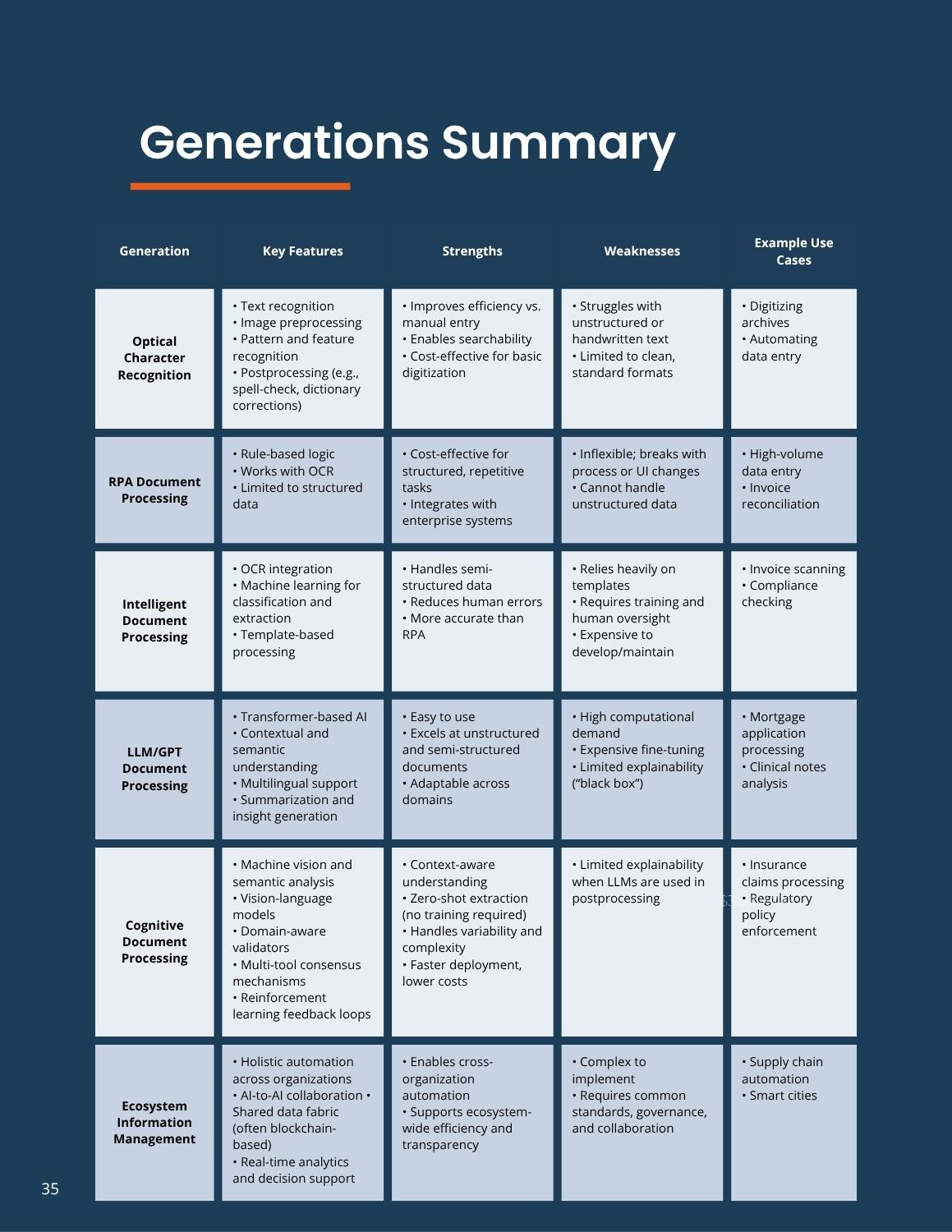
Table 1: Comparison of Generations of Document Processing Technologies
Metrics That Matter
To avoid the “Legacy Plateau”—planning driven by inflated accuracy on easy cases and hidden exception costs—and to strengthen observability, ground your automation program in a concise, outcome-focused KPI set.
Key Metrics
- Useful Accuracy (across all documents)
- Definition: Correct field/decision outputs ÷ total items, including exceptions and edge cases.
- Why it matters: Counters selective “STP-only” claims and reflects true business quality.
- Straight-Through Processing (STP) Rate
- Definition: Cases completed with zero human intervention ÷ total cases.
- Why it matters: Measures actual autonomy and end-user impact in terms of speed and effort.
- Time-to-Adapt (TTA)
- Definition: Elapsed time from a breaking change (UI, policy, vendor) to restored SLA/accuracy.
- Why it matters: Captures agility and limits the cost of downtime.
- Maintenance Load
- Definition: (Rules/templates/models edited per month + operational hours spent on upkeep) ÷ total operational hours.
- Why it matters: Serves as a direct proxy for the ongoing cost of ownership.
- Resilience After UI/Vendor Change (Resilience Index)
- Definition: Post-change throughput (first 7–14 days) ÷ baseline throughput.
- Why it matters: Demonstrates how well automations endure real-world drift.
- Trace/Lineage Completeness
- Definition: % of cases with full perception ? prediction ? reasoning ? action record (inputs, versions, tool calls, decisions).
- Why it matters: Enables auditability, regulatory compliance, and faster root-cause analysis.
Conclusion
The evolution of document processing technologies, from OCR and RPA to IDP, GPT/LLM processing, CDP, and eventually EIM, has been driven by the pursuit of greater efficiency, accuracy, and scalability in managing ever-growing volumes of business-critical information. OCR and RPA introduced the first wave of automation for simple, rule-based tasks. IDP added machine learning to handle semi-structured data, while GPT/LLMs brought contextual language understanding. CDP’s perception-first/ understand-before-act approach advances the field with adaptability, continuous learning, and self-correction without extensive training. EIM is the logical network-level extension of CDP: a fully interconnected and collaborative environment built on next-generation digital infrastructure, where all prior innovations converge.
As organizations adopt more advanced document processing technologies, they gain the ability to manage increasingly complex and unstructured documents with less human intervention. This shift amplifies the value of document-derived insights and enables faster, more reliable business processes.
Businesses implementing solutions such as CDP can unlock significant operational efficiencies and competitive advantages, including reduced processing costs, accelerated decision-making, and improved agility. However, realizing these benefits requires more than just technology. Success depends on thoughtful planning, investment, employee training, process redesign, and effective change management. With the right preparation, these technologies deliver substantial return on investment while boosting productivity and responsiveness.
Ultimately, the question for most organizations is not whether to automate document processing, but how far and how quickly they must advance to remain competitive in an AI-driven future.



