Syncura Cognitive Document Processor
Syncura CDP is a zero-shot cognitive document processor built to handle the long tail of document variability that resists conventional extraction. Variable formats, missing fields, handwritten annotations, stamps, and inconsistent structures are processed with ease. CDP requires no model training and approaches documents the way a trained human would. It understands context, recognizes intent, and knows when something needs a second look.
The problem
Most document extraction systems perform well on predictable cases. The challenge is that real enterprise document workflows are filled with unpredictable ones.
Format variability
Invoices, contracts, and forms arrive in countless layouts from a wide range of sources. Intelligent document processing systems that rely on trained models are limited to the document types they were designed for, and template-based extraction requires a unique template for each variation. When a supplier changes their format, the document data extraction breaks.
Missing and inconsistent data
Fields may appear in different locations, use varying terminology, or be missing altogether. Conventional document processing struggles outside its predefined scope, causing exceptions to accumulate and requiring manual intervention that doesn’t scale.
Constant maintenance overhead
Every new document type demands extra engineering effort. Every format change requires retraining or re-templating. Document processing that was meant to reduce operational overhead often creates an additional layer of it.
How it works
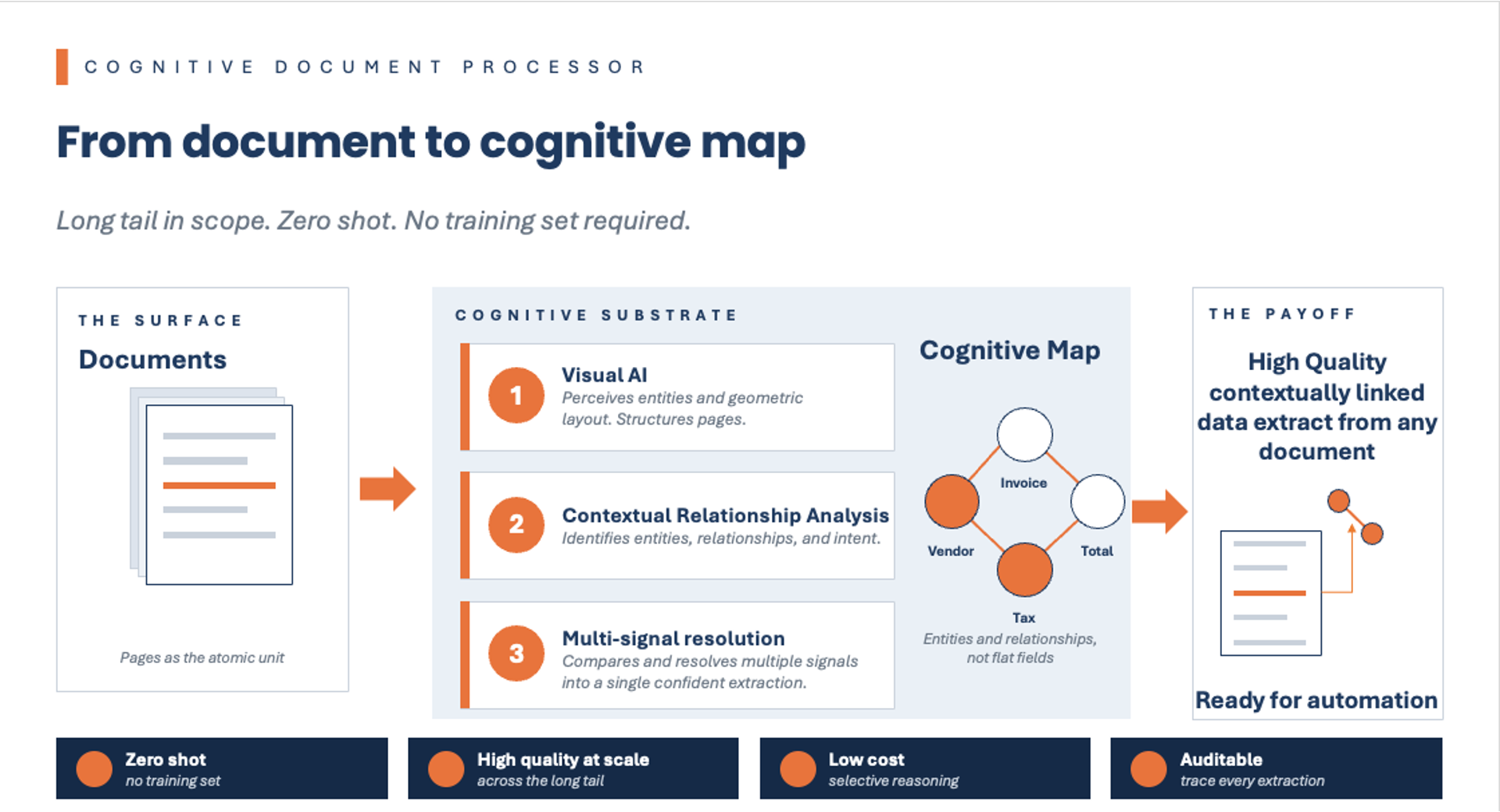
CDP processes documents the way a trained human reviewer would. It reads the entire document using multiple strategies, understands relationships between data elements, determines what each piece of data represents in context, and maps it to a defined business schema.
This goes beyond optical character recognition and traditional machine learning models. OCR reads characters. Trained models rely on patterns learned from prior examples.
CDP operates differently. It interprets meaning through context. A number in a subtotal row is treated as a line-item total, not a document total. A date in a header is recognized as an invoice date, not a payment date, and can be normalized into a standard format. Even details like time zone can be inferred from surrounding information such as an address. Context determines what data means and where it belongs.

Outcomes
No setup delay
Because CDP processes documents through contextual understanding rather than learned patterns, there is nothing to train before it can begin. A new document type can be processed accurately the first time it is seen. The time between identifying a document processing need and running it in production is days, not months. Conventional IDP implementations typically require weeks of template configuration and model training before a single document can be processed reliably.
Higher straight-through processing rates
CDP understands what data means in the context of the document it came from, not just where it appears on the page. This contextual understanding means more documents meet the STP threshold and pass through without human intervention. The variability that causes conventional automation to fail and route documents to exception queues is absorbed within the processing layer. More work gets through automatically, with the confidence scores to back it up.
Fewer exceptions, less manual handling
When fields are missing, ambiguous, or require inference rather than extraction, CDP resolves them rather than failing. Human reviewers receive only the documents that genuinely require judgment, surfaced with the specific fields that need attention. In conventional document processing, any deviation from the expected format generates an exception. CDP handles the deviation and only escalates when the confidence threshold is not met.
Output your downstream systems can actually use
CDP delivers structured JSON aligned to your defined business schema, ready for direct consumption by the systems that depend on it. Implicit values are inferred, derived fields are calculated, and data is normalised before it leaves the processing layer. There is no transformation logic sitting between the extraction output and the workflows that need it. Egress is configurable via API, webhook, or other integration method.
Stable performance as environments change
Document formats evolve. Vendors update templates. New document types enter production. In conventional document processing, each change triggers a maintenance cycle that erodes the efficiency gains the automation was supposed to deliver. CDP adapts without intervention. The extraction profiles that govern processing are updated when requirements change, and the processing engine handles the rest. Performance holds as the environment changes rather than degrading with it.
Governance and auditability built in
Every extraction decision, every confidence score, and every routing outcome is logged and traceable. Because processing is deterministic rather than probabilistic, every output can be explained in terms of the specific data points and confidence levels that produced it. Regulated industries require this level of traceability as a baseline compliance requirement. CDP provides it without additional tooling, reporting layers, or manual audit processes.
How documents flow through CDP
Every document follows a governed path from ingestion to delivery. The architecture is designed to maximize straight-through processing while keeping humans involved where they add real value.
Documents enter the system through API, webhook, in basket, automation or portal. If needed, a preprocessor can scan and route documents to queues configured to process a particular document type. Each queue is associated with a Profile that defines what data to extract, how data elements relate to one another, and how output maps to your target business schema. Profiles separate business configuration from the processing engine, so when requirements change, you can update the profile rather than reconfiguring the system. New document types can be introduced by simply creating a new profile, while the processing engine continues to operate.
During processing, confidence scores are generated for every extracted field. These are aggregated into a document-level confidence score. A confidence threshold defines when documents can move automatically to straight-through processing. Documents that fall below the threshold are routed to human review.
Once a document passes straight-through processing or is approved through review, it moves to egress. Output is delivered as structured JSON file aligned to your defined schema. Egress can be configured for API delivery, webhooks, or other automation patterns, sending high quality, clean, normalized data directly to downstream systems.
Use cases
CDP handles variable documents across industries where extraction accuracy and processing speed are critical.
Invoice and accounts payable processing
Extract line items, totals, and supplier data from invoices in many formats. Enable straight-through processing for clean documents, with human review only where necessary.
Insurance claims document processing
Process claims submissions, medical records, and supporting documents. Extract relevant data and route it to the appropriate workflow stage.
Trade and logistics documents
Handle bills of lading, customs declarations, and shipping documents from any carrier in most languages, with minimal human intervention. Normalize data elements for downstream processing.
Contract and legal document extraction
Extract key terms, dates, parties, and obligations from contracts and legal documents. Adapt to varied structures and non-standard drafting styles.
Clinical and healthcare records
Process clinical notes, discharge summaries, referrals, and prior authorization documents, including handwritten and scanned records. Maintain data accuracy and comply with regulatory oversight.
Financial statements and regulatory filings
Extract and normalize data from financial statements, regulatory filings, and reporting documents across institutions and jurisdictions.
See CDP work
We use real documents, yours or representative examples from your industry. 30 minutes. No slides.