
Key Messages
- Documents sit at the heart of nearly every business and governmental process. They carry instructions, encode transactions, and hold most of the unstructured information that organizations rely on.
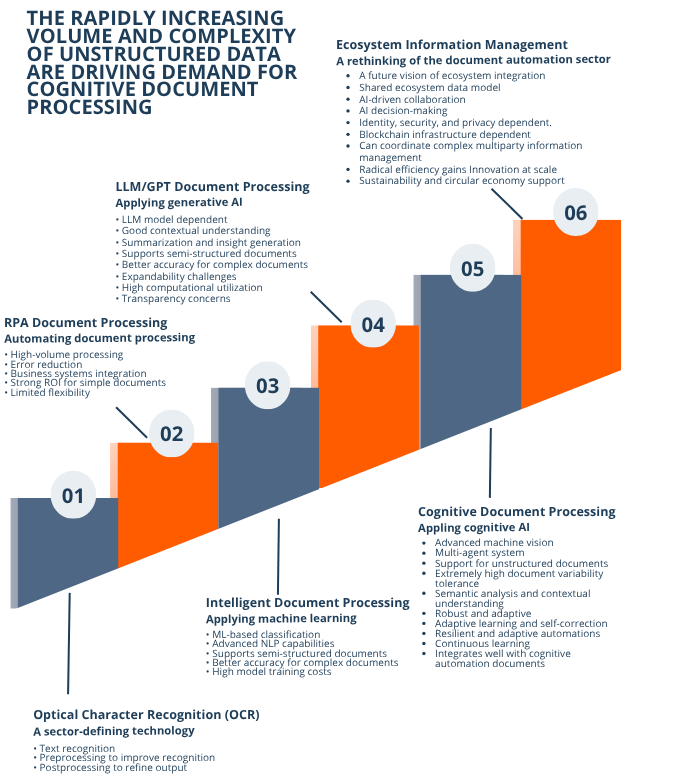
- Document processing technology has advanced through six recognizable generations, each one extending what was possible and each one running into structural limits that the next generation set out to address.
- The most advanced generation available today, cognitive document processing, defines cognitive AI as a collection of complementary technologies rather than a single model. In the document context this collection includes visual AI, document geometry analysis, handwriting recognition, deep learning OCR, and vision-language model analysis and reasoning.
- Cognitive AI is the first generation that genuinely reaches the long tail of variable, unstructured, and imperfect documents that has historically resisted automation. It does so through zero-shot processing, sight-unseen, with no model training or template setup.
- A sophisticated document confidence algorithm decides which documents proceed straight through and which are routed to highly productive human-in-the-loop review for the truly exceptional cases.
- Each generation deserves to be understood on its own terms. Most enterprises are running a mix of these technologies today, and understanding the evolution is a useful foundation for deciding what to invest in next.
Introduction
Documents are fundamental to almost all business and governmental operations. They are used to encapsulate information, convey instructions, and record transactions. Document processing involves extracting their content, understanding their meaning and significance, and transferring their information to business systems.
Documents can be physical and digital, and there are a lot of them. In global trade sector alone, there are approximately four billion documents in circulation on any given day. It is estimated that there are more than 2.5 trillion PDF documents in the world.
In 2025 we generated approximately 181 zettabytes of new data, and 80 to 90 percent of that was unstructured. Considering the massive volume of documents and their critical importance to the functioning of business processes, it is not surprising that businesses and governments have invested enormous effort to digitize and automate document handling and processing.
What is interesting, and the subject of this paper, is how unevenly that investment has paid off. Standardized invoices and structured application forms are largely solved. The cost lives in the long tail of everything else: multiparty contracts with cross-referenced amendments, physician notes with handwritten annotations, customs declarations in unfamiliar formats, customer correspondence, and the broad category of documents that do not conform to a stable template. Industry estimates suggest that 70 to 80 percent of the documents organizations would like to automate remain beyond the reach of traditional approaches. That is where the operational cost quietly accumulates, and it is the gap that each successive generation of document processing has tried, with varying degrees of success, to close.
The Evolution of Document Processing
Until the late 1980s, documents were processed entirely by people. Humans are highly adept at interpreting documents, improving with experience and requiring little formal training to adapt to new document types. We are flexible and capable of handling significant variability. But people are also expensive resources, and our output, both in quality and throughput, varies widely. Eventually the volume of documents exceeded the capacity of manual workforces to keep pace, and organizations turned to technology to digitize and manage them at scale.
Over the past thirty years, document processing has advanced through several waves of innovation. Each wave introduced a genuinely new capability. Each one improved quality and advanced what was possible. And each one eventually ran into a wall that the next generation had to step around. Optical character recognition unlocked digitization. Robotic process automation wired that digitization into the rest of the enterprise. Intelligent document processing brought machine learning to bear on classification and extraction. Large language models brought contextual understanding to unstructured text. Cognitive document processing brings the full collection of cognitive AI techniques together so that, for the first time, the long tail is genuinely in reach.
It is tempting to tell this story as a progression of failures redeemed by the latest technology. That would be wrong. Each generation succeeded at what it was designed to do, and each one is still doing useful work somewhere. OCR, for instance, is a product of an earlier generation that the contemporary approach absorbs and uses every day. The honest story is one of accumulation, not replacement. Cognitive AI is the first generation that finally reaches the long tail, but it does so by standing on the shoulders of everything that came before.
This paper examines the five most recent generations of document processing technology: OCR, robotic process automation document processing, intelligent document processing, large language model document processing, and cognitive document processing. It also looks ahead to the potential emergence of ecosystem information management. For each generation we will explore the technologies involved, how they integrate with broader business processes, their genuine strengths and structural limitations, and the kinds of work they are best suited to.
Generation 1: OCR
Optical character recognition detects characters in document images by analyzing their shapes and converting them into machine-readable text that can be used in digital systems. It is the foundation on which every later generation has been built.
Preprocessing
After a document is captured, preprocessing techniques such as noise removal, de-skewing, and binarization are applied to enhance clarity and improve recognition accuracy.
Postprocessing
Once characters are recognized, postprocessing methods such as spell-checking, dictionary-based corrections, and natural language processing refine the output and correct errors.
Strengths
Traditional OCR performs well on clean, printed text in standard fonts. Although it struggles with noisy or unstructured documents, OCR marked a major leap in efficiency, enabling faster document processing, improved searchability, and significant cost reduction compared with manual methods. Forty years on, OCR is still doing useful work in archives, mailrooms, and form-processing pipelines around the world.
Limitations
OCR is far less effective for semi-structured, unstructured, or handwritten text. Its standalone utility is limited in many real-world document processing scenarios without the support of complementary technologies. The honest reading is that OCR converts shapes to characters. It does not, on its own, understand what the characters mean.
Key Characteristics of OCR
- Text recognition. Converts printed or handwritten text into machine-readable formats.
- Image preprocessing. Enhances input quality through techniques such as noise reduction, de-skewing, and binarization.
- Pattern and feature recognition. Identifies characters and symbols based on their shapes and structures.
- Language and font versatility. Supports multiple languages, character sets, and font styles.
- Flexible output formats. Delivers results in formats such as plain text, searchable PDFs, or structured data.
- High scalability. Processes large document volumes efficiently across industries.
- Pre- and postprocessing support. Incorporates spell-checking, dictionary corrections, NLP, and other refinements to improve accuracy.
Example Use Cases for OCR
DOCUMENT DIGITIZATION FOR ARCHIVING
An insurance company uses OCR to convert physical documents, such as manuals, contracts, and records, into digital formats. This reduces reliance on physical storage while making critical information more searchable and accessible across the organization.
AUTOMATED DATA ENTRY FROM FORMS
A shipping company applies OCR to extract text automatically from structured forms, including invoices, receipts, and applications. This automation eliminates manual data entry, saving time, reducing errors, and improving operational efficiency.
As revolutionary as OCR was, it has always been limited. Over time, the technology has been enhanced with complementary tools to improve both its accuracy and its practical usefulness. The next major step in document processing came with its integration into robotic process automation.
Generation 2: Robotic Process Automation Document Processing
The digitization of documents is not only a standalone process but also a critical part of broader business workflows. Robotic process automation offered an efficient way to streamline these workflows, and as a result OCR and RPA have become closely linked and are often packaged together.
Repetitive Task Automation
RPA document processing excels at automating repetitive tasks such as invoice processing and patient data management. It uses OCR to read, interpret, transform, and classify documents, while automations or bots load the extracted data into databases and enterprise resource planning systems for use in downstream processes. Because it relies on rule-based logic and predefined templates, RPA is well suited for handling large volumes of structured documents in predictable formats.
Strengths
RPA document processing is highly effective at digitizing simple, structured documents. It enables organizations to process documents at scale with low costs and high quality, reduces human error, and allows staff to be redeployed to higher-value tasks. Compared with more advanced AI-driven systems, RPA also requires lower upfront investment and has a lower overall cost of ownership, which makes it an attractive choice for straightforward use cases.
Limitations
RPA document processing is restricted to simple, structured, and non-variable documents that conform to fixed formats. In practice, most organizations also deal with large volumes of complex, unstructured, or variable documents that RPA cannot handle effectively. Because RPA depends on static rules and templates, it lacks adaptability and requires constant maintenance when document formats change.
Some organizations have managed to extend RPA to moderately complex documents through extensive coding, customization, and exception handling. These solutions tend to remain fragile and still lack genuine adaptability. RPA is further limited by its inability to interpret the meaning of data elements, the relationships between them, or the broader context of the document. The result is that its utility is confined to basic data extraction, which restricts the overall business value of the information it captures.
Key Characteristics of RPA Document Processing
- Extends OCR capabilities. Builds on OCR to automate data extraction and entry.
- Optimized for structured documents. Well suited to high-volume, predictable formats such as invoices or forms.
- Strong return on investment for simple automations. Delivers cost savings and efficiency in repetitive, rules-based tasks.
- Error reduction. Minimizes human transcription errors by automating data handling.
- Broad system integration. Connects with a wide range of enterprise platforms and applications.
- Limited flexibility. Struggles with variability, semi-structured, or unstructured documents.
- Lacks contextual understanding. Cannot interpret meaning or relationships beyond predefined rules.
Example Use Cases for RPA Document Processing
INVOICE PROCESSING
A finance department uses RPA document processing to extract invoice data, vendor details, and payment terms. A bot then transfers the extracted data into the organization's accounting system for approval. This automation reduces manual effort, improves efficiency, and accelerates payment cycles.
FORMS PROCESSING
A healthcare provider applies RPA document processing to scan and extract patient information from structured admission forms. A bot transfers the data into the patient management system, reducing administrative errors and shortening wait times. Automating this process enhances the patient experience while improving operational efficiency.
RPA document processing was the norm until the mid-2010s when AI technologies began to add comprehension capabilities to document processing.
Generation 3: Intelligent Document Processing
Intelligent document processing extends RPA document processing with machine learning technologies such as deep learning, neural networks, machine vision, and natural language processing. These advances revolutionized how digital text, handwriting, and image-based data are handled, enabling IDP systems to classify documents and extract key information from both structured and semi-structured formats. IDP is significantly more capable of managing different versions of the same document type, including complex invoices, purchase orders, and emails, which makes document processing meaningfully more valuable to organizations.
Classification
By leveraging machine learning's ability to recognize patterns, IDP provides far more advanced classification capabilities than earlier generations. Information can be routed automatically with minimal human input. IDP can categorize incoming documents such as invoices or contracts and forward them directly to the appropriate department, which reduces manual intervention and makes it easier to integrate document content into complex business processes.
Data Extraction and Interpretation
Beyond classification, IDP excels at extracting and interpreting document content. With the support of machine learning and NLP, it can analyze and accurately capture key data elements such as names, dates, places, and amounts, providing richer insights for downstream systems.
The Training Cost Problem
Despite its strengths, IDP depends heavily on training with large volumes of labeled, domain-specific documents. Industry rules of thumb suggest around 2,000 samples for semi-structured documents and 10,000 or more for unstructured formats. This makes IDP expensive to set up and slow to adapt. Worse, training itself narrows the system. Models tuned to a specific document type perform well within those boundaries and degrade quickly outside them. Many vendors publish headline accuracy figures of 95 percent or higher that obscure this reality, because the figures are typically measured only on documents that pass straight-through processing. That subset may represent as little as 25 percent of total volume, with the remaining 75 percent falling back to manual handling.
Contextual Understanding
While IDP is more capable than RPA at interpreting documents, its ability to understand context and the relationships between data elements remains limited. This restricts its usefulness in scenarios that require informed decision-making or high levels of data accuracy in downstream business processes.
Key Characteristics of Intelligent Document Processing
- Machine learning-driven classification and extraction. Identifies document types and extracts key fields with greater intelligence than rule-based systems.
- Enhanced OCR accuracy. Provides more reliable text recognition compared with traditional OCR.
- Advanced NLP capabilities. Interprets context, entities, and relationships within documents.
- Support for semi-structured documents. Handles formats such as invoices, purchase orders, and forms with variable layouts.
- Reduced human intervention. Requires human-in-the-loop validation for fewer documents.
- Template dependence. Performance is often tied to the quality and relevance of templates.
- High development and maintenance costs. Model training and upkeep demand significant time, data, and resources.
- Limited scalability for complex processes. Struggles to extend beyond semi-structured tasks or highly variable documents.
Example Use Cases for IDP
INSURANCE CLAIM PROCESSING
An insurance company uses IDP to process claim forms, classifying documents, extracting key data such as policy numbers and claim amounts, and passing that information to a business process. This improves response times and reduces costs.
EMAIL PROCESSING
A customer service department uses IDP to classify incoming emails based on content and automatically routes them to the correct team. This reduces response times and improves customer satisfaction by ensuring emails are directed appropriately and efficiently.
IDP's use of machine learning and deep learning enabled it to handle a much wider variety of documents than its predecessors. Its ability to interpret different data types significantly improved classification and made information more valuable to businesses. Yet the training burden, the narrowing effect of specialization, and the limited contextual understanding kept IDP from reaching the long tail. Organizations increasingly needed systems that could deal with unfamiliar documents without weeks of data preparation, and the next generation began to offer that promise.
Generation 4: Large Language Model Document Processing
Document processing advanced significantly with the advent of transformer-based AI. Generative pretrained transformers and large language models introduced deeper contextual understanding, making it easier to extract insights from unstructured text. For the first time, a document processing system could read a paragraph and produce a meaningful summary, identify the parties to a contract, or surface the key obligations in a regulatory filing.
Contextual Understanding
Large language models are particularly valuable in the downstream interpretation stages of document workflows. Once documents have been ingested, they can interpret both context and content, streamlining tasks that previously required extensive manual effort, such as analyzing complex contracts, identifying key clauses, and generating summaries within seconds. Their ability to understand context across multiple languages and domains makes them versatile tools for industries operating in diverse geographies.
Explainability and Hallucination
However valuable the contextual insights produced by these models can be, the way they reach their conclusions is problematic. At its core, a large language model is a probabilistic system that generates outputs by predicting the most statistically likely next token (segment of a word). It does not reason in the way the term is commonly understood. It approximates reasoning through pattern completion.
The practical consequence is twofold. First, outputs are non-deterministic: given identical inputs, the same model may produce slightly different outputs on different runs. Second, models are susceptible to hallucination, producing plausible-sounding statements that are not grounded in the source material. For consumer applications this is tolerable. For regulated document workflows, where a clause interpretation must be the same each time and where a fabricated detail can have downstream consequences, it is a structural concern rather than a curiosity to be managed with logging.
Layout Blindness
Text-only LLMs are also blind to layout. A signature block, a stamp, a hand-annotated correction in the margin, or a value sitting in a particular cell of a complex table all carry meaning that does not survive when a document is reduced to plain text. Vision-language models, which can attend to images and layout as well as text, address part of this, but the underlying point remains. Reasoning over poorly structured inputs amplifies error rather than correcting it. A strong perception layer in front of any language model dramatically improves the quality of what comes out.
Costs
Deploying large language models for document processing often requires fine-tuning for specific industries and tasks. This is expensive and time-consuming, requiring domain expertise and large volumes of labeled training data. The models also demand significant computational resources at inference time (runtime), which makes large-scale deployments costly. Token consumption is highly variable: a clean run is predictable, but unexpected content or complex documents can consume multiples of that. At enterprise scale, this makes cost forecasting unreliable.
Key Characteristics of Large Language Model Document Processing
- Contextual understanding. Interprets meaning beyond keywords, capturing nuance and intent in documents.
- Multilingual capability. Processes and analyzes content across many languages with high accuracy.
- Domain adaptability. Applies knowledge flexibly across industries and subject areas without retraining for every use case.
- Summarization and insight generation. Produces concise overviews, extracts key points, and identifies patterns within large bodies of text.
- Strength in unstructured data. Excels at handling unstructured and semi-structured documents such as emails, contracts, and reports.
- Explainability challenges. Functions as a black box, making it difficult to trace reasoning or validate outputs.
- Non-deterministic outputs. Identical inputs may produce different outputs on different runs.
- Hallucination risk. May produce plausible but ungrounded statements, particularly when input quality is poor.
- High computational demand. Requires substantial resources for training and inference, driving up operational costs.
Example Use Cases for Large Language Model Document Processing
MORTGAGE APPLICATIONS
A financial services company leverages LLM-based document processing to extract critical information, such as income, assets, and liabilities, from lengthy mortgage applications. This automation streamlines a traditionally time-consuming step in the home-buying process, reducing bottlenecks and accelerating approvals.
CLINICAL NOTES ANALYSIS
A hospital applies LLM-based document processing to analyze clinical notes, extract key patient data, and surface preliminary observations from patient records. This improves the use of hospital resources and helps patients receive better care, faster.
Large language models are a genuine advance, and they have a permanent place in the document processing stack. The lesson of this generation is not that the technology is wrong, but that using a single general-purpose model as the universal runtime is the wrong architectural choice. The strongest results come when language model reasoning is combined with visual AI that structures and contextualizes inputs before the model is asked to interpret them, and when the model is applied selectively rather than to every step. That insight is the foundation for the next generation.
Generation 5: Cognitive Document Processing
Cognitive document processing is the contemporary generation, and it is the first that genuinely addresses the long tail. It is also the generation that most resists being explained as a single technology. Cognitive AI, as applied to documents, is not one model or one technique. It is a collection of complementary technologies and strategies working together, each handling the part of the problem it is best suited to.
In the document processing context, that collection includes visual AI, document geometry analysis, handwriting recognition, deep learning OCR, and vision-language model analysis and reasoning. None of these is new in isolation. What is new is how they are combined, the order in which they operate, and the discipline applied to when each one is invoked.
Cognitive AI as a Collection of Technologies
It is tempting to look for a single model that can solve the document processing problem. Human cognition, applied to expert work, is not a single faculty, and the most effective systems are not built on a single capability either. When a skilled underwriter reviews a loan file, visual perception structures the page before conscious analysis begins. Interpretive faculties then map relationships between entities, connecting income to employer and employer to tenure. Only after this structuring does deliberate reasoning come into play, evaluating the file against policy and identifying edge cases. The underwriter does not reason about every detail. Reasoning is applied selectively, where judgment is required, while the rest is handled by faster, more automatic processes.
Cognitive document processing operates in much the same way. Each layer has a specific role, and the role of one is not delegated to another.
- Visual AI perceives and structures the page before any reasoning begins. It is the foundation. Without reliable perception, every downstream component is working from corrupted input and small errors compound.
- Document geometry analysis identifies layout, hierarchy, tables, headers, signatures, stamps, and the spatial relationships between elements. It turns a page from a flat surface into a structured object with known parts.
- Handwriting recognition brings handwritten content into the same processing pipeline as printed text. Physician notes, annotated invoices, signed authorizations, and field-completed forms move from manual handling into automation.
- Deep learning OCR extracts text reliably from noisy, low-quality, or otherwise difficult inputs. It is itself a product of an earlier generation that cognitive AI absorbs and uses every day, applied where it does its best work.
- Vision-language model analysis and reasoning interprets content in the context of layout, resolves ambiguity, and applies selective judgment where it is genuinely required. Crucially, this reasoning is invoked deliberately rather than at every step.
The combination is the point. Visual AI can perceive but cannot interpret. Geometry analysis without strong perception rests on an unstable foundation. Reasoning without the other layers is inefficient and prone to error. Together, these layers create a system that is accurate, cost-efficient, adaptable, and auditable, with each layer producing traceable outputs that support governance and compliance.
Why the Long Tail Was So Hard
Document variability in the long tail is a common and expensive reality that has resisted automated processing for decades. The reason is not lack of effort. Standardized invoices and structured application forms are largely solved by intelligent document processing, but only within the narrow conditions for which those systems were trained. The cost lives in everything else. Multiparty contracts with cross-referenced amendments. Physician notes with handwritten annotations alongside printed text. Customs declarations in unfamiliar formats. Customer correspondence in any number of styles. First notice of loss reports composed under stress and in haste. Each of these documents is, in its own way, irregular. Each of them resists template-based extraction. Each of them, at scale, ends up routed to a human.
Earlier generations could not address this long tail cost-effectively. RPA required predictable layouts. IDP required labeled training samples that were difficult to assemble for documents that, by definition, did not look like one another. Large language models offered context but stumbled on layout and could not be relied on to behave the same way twice. The cognitive AI approach addresses the long tail because it understands documents structurally before it tries to interpret them, because it brings the right tool to bear on each subproblem, and because it knows when it is uncertain.
Zero-Shot Processing
The cognitive AI approach enables true zero-shot processing. Documents can be processed without model training, without labeled sample sets, and without template building. The system applies its underlying cognitive framework to documents it has not previously encountered, in much the same way that a human expert approaches an unfamiliar document type by recognizing its shape, finding the entities and relationships, and applying judgment where the layout is ambiguous.
In practice, extraction requirements are defined as a declaration of intent rather than a template. A user describes the fields and tables they need, names them as they will appear downstream, and adds light guidance about format or validation. There is no training step. There are no labeled samples. The system identifies the relevant information regardless of where it sits on the page or how the surrounding document is structured. The implication is significant. Onboarding a new document type drops from weeks to hours, and the bottleneck shifts from data preparation to clear thinking about what needs to be extracted.
Confidence-Driven Straight-Through Processing
Ambition without safety is a liability. The mechanism that makes cognitive document processing both ambitious and safe is a sophisticated document confidence algorithm. As each document is processed, the system produces an overall confidence score for the extraction, informed by the confidence of each individual field, the consistency of relationships between fields, and the agreement among the multiple cognitive techniques that examined the page.
If the confidence exceeds the threshold set for that document type or workflow, the document proceeds straight through. The data flows directly to the downstream system, with no human in the loop. If the confidence falls below the threshold, the document is routed for review. The threshold is configurable, which means that an organization can dial the system toward maximum throughput for low-stakes documents and toward maximum caution for documents where errors are costly. Confidence is the lever that lets the same underlying technology serve both an invoice queue and a regulatory filing queue without compromise.
Highly Productive Human-in-the-Loop Review
The point of cognitive document processing is not to eliminate human involvement. It is to concentrate that involvement on the documents that genuinely need it. When a document is routed for review, the goal is to make the reviewer as productive as possible.
A well-designed review experience presents the source page alongside the extracted data, with each data element traceable to its origin on the page. Clicking a field highlights the location where the value was extracted. Tables, layout elements, and free text are organized into logical tabs that a reviewer can move through quickly. Corrections are saved as they are made. Once the document is released, downstream processing continues. The reviewer is not re-keying from scratch. They are validating the work that the system has done and intervening only where it falls short. In practice, organizations adopting this approach see review times for exceptional documents drop dramatically while the proportion of documents that need review keeps shrinking as the system matures.
Selective Use of Reasoning
One of the most important architectural choices in cognitive document processing is the discipline applied to when vision-language model reasoning is invoked. The lessons of Generation 4 are well learned. Using a general-purpose language model as the runtime for every step is non-deterministic, opaque, and expensive at scale, and the recent enthusiasm for using such models as live agentic runtimes risks repeating the same mistakes in a new form.
Cognitive AI applies reasoning deliberately. Most of the work is done by efficient, deterministic components: visual AI, geometry analysis, OCR, and rule-based validators. Vision-language model reasoning is brought in where it is genuinely needed, typically to resolve ambiguity that the lower layers have surfaced, to interpret content in the context of layout, or to make a judgment call where a deterministic rule cannot reach. This selective use of reasoning preserves the things that matter most at enterprise scale: predictable cost, predictable behavior, and an auditable trail of how each decision was reached.
Key Characteristics of Cognitive Document Processing
- Multi-technology architecture. Combines visual AI, document geometry analysis, handwriting recognition, deep learning OCR, and vision-language model reasoning, each applied where it does its best work.
- Perception before interpretation. Structures the page before any reasoning is invoked, dramatically improving the quality of downstream outputs.
- Zero-shot processing. Handles novel document types without model training, labeled samples, or template construction.
- Declaration of intent. Extraction requirements are described by the user as the fields and tables they need, not as templates to be matched.
- Confidence-driven straight-through processing. A sophisticated confidence algorithm determines whether a document can pass straight through or should be routed for review.
- Highly productive human-in-the-loop review. Reviewers see the source page alongside the extracted data, with each data element traceable to its origin, and concentrate their effort on the truly exceptional cases.
- Selective use of reasoning. Vision-language model reasoning is applied deliberately, not at every step, which preserves cost predictability and behavioral consistency.
- Auditable by design. Each cognitive layer produces traceable outputs, supporting governance and regulatory compliance.
- Continuous improvement. Reviewer corrections feed back into the system, strengthening it over time without retraining from scratch.
Example Use Cases for Cognitive Document Processing
CONTRACT ANALYSIS
A legal department uses cognitive document processing to analyze complex contracts, automatically identifying key clauses, obligations, and risks across documents that vary widely in structure. The system highlights areas requiring review or negotiation and traces every extracted obligation back to its source in the document, allowing legal teams to focus on higher-value strategic work.
LOAN ORIGINATION
A lender processes paystubs, tax returns, bank statements, investment statements, and correspondence as part of mortgage and consumer loan underwriting. Cognitive document processing handles the long tail of layouts these documents come in, including handwritten annotations, with no per-bank or per-employer template required, accelerating decisions while preserving the audit trail that regulators expect.
FIRST NOTICE OF LOSS
An insurer ingests first notice of loss reports, adjuster notes, photographs, and supporting documents, often arriving in inconsistent formats and under time pressure. The system extracts the key facts, flags the truly exceptional cases for human review, and feeds the rest directly into claims systems, compressing time-to-decision and reducing the operational cost per claim.
REGULATORY POLICY ENFORCEMENT
An energy company applies cognitive document processing to inspection reports, permits, environmental impact assessments, safety audits, and emissions logs. The system extracts critical data and cross-references it against local and international regulatory standards, flagging anomalies or potential non-compliance issues in real time.
Cognitive document processing is the first generation to bring genuine zero-shot capability, layout-aware reasoning, and a disciplined approach to human involvement into a single coherent system. It does not claim to solve every document processing problem. It does claim to reach the long tail that earlier generations could not, and to do so with the cost predictability, transparency, and governability that enterprise deployment requires.
Generation 6: Ecosystem Information Management
The future of document processing is likely to evolve into ecosystem information management. EIM extends the capabilities of cognitive document processing and cognitive process automation across firms through shared data and control planes, with blockchain-backed fabrics providing identity and provenance. The intent is to integrate AI-driven document processing into broader business ecosystems. Unlike earlier generations, which focused on departmental or use-case-specific automation, EIM aims to create a fully interconnected environment that enhances collaboration and enables real-time decision-making across business networks.
Cross-Ecosystem Workflows
EIM will process documents in real time as part of end-to-end automated workflows spanning multiple systems and organizations. An EIM platform could connect customer relationship management and compliance systems across companies, ensuring that customer data is accurately processed and verified without manual intervention. These systems move beyond simply extracting data, treating documents as components of an interconnected information ecosystem rather than isolated data sources. This perspective enables more comprehensive, ecosystem-wide decision-making.
Data Fabric
EIM relies on advanced cognitive and reasoning AI, real-time data sharing, agentic workflows, and interoperability via a shared data fabric, often supported by blockchain infrastructure. This enables organizations to operate in highly coordinated, efficient, and collaborative configurations. Blockchain services add essential identity and reputation mechanisms, giving participants confidence in the authenticity of documents and the integrity of associated metadata.
Efficiency
EIM reduces manual input and duplication in workflows such as data entry and document verification. It manages documents and their embedded information as part of a broader, integrated process and can process and analyze documents in real time. By linking multiple businesses through shared systems, EIM eliminates silos and improves overall operational efficiency.
Challenges
While EIM promises radical efficiency gains and innovation at scale, it requires substantial investment in infrastructure, process redesign, and the development of interoperability standards and decentralized governance systems. Technical hurdles include integrating diverse systems, ensuring data compatibility across platforms, protecting data privacy, and multiparty governance, coordinating among stakeholders with varying technological capabilities. EIM adoption also demands a cultural shift as businesses adapt to fully automated, real-time, multiparty operations.
Key Features of Ecosystem Information Management
- Holistic integration. Connects workflows and data across ecosystem partners for seamless collaboration.
- Shared data environment. Provides a trusted, unified platform for information exchange.
- Real-time document processing. Embeds automated document handling directly into business systems.
- Real-time analytics and decision support. Delivers instant insights to guide operations and strategy.
- AI-driven decision-making. Applies advanced models to evaluate scenarios and recommend optimal actions.
- AI-to-AI collaboration. Enables autonomous agents from different organizations to coordinate and share insights.
- Integrates smoothly with multiple backend systems across the ecosystem.
- Ecosystem-wide efficiency. Enhances speed, accuracy, and productivity across interconnected enterprises.
- Security and privacy management. Ensures compliance, governance, and protection of sensitive information.
- Reliance on blockchain-based infrastructure. Depends on complex digital frameworks to enable trust, provenance, and decentralized governance.
Example Use Cases for EIM
PROCUREMENT AUTOMATION
A multinational corporation with complex multiparty supply chains uses EIM to automate an entire procurement process, from receiving purchase orders to negotiating contracts, managing suppliers, and processing payments. This significantly reduces procurement cycle times and minimizes human errors, enhancing overall efficiency.
LEGAL COMPLIANCE
A financial institution facilitating trade finance uses EIM to automatically analyze and process regulatory documents across multiple jurisdictions, ensuring real-time compliance with changing legal requirements. This helps avoid penalties and improves audit readiness, providing greater operational assurance.
EIM and the associated ecosystem economy imply both a technical and a behavioral complexity that will be difficult to overcome. Like all technology and business change, it will not just appear. It will evolve. We will likely see the technology, change management, and cultural changes required to support EIM manifest first inside large companies and then inside highly concentrated ecosystems. Eventually, highly composable ecosystems will emerge that leverage digital infrastructure including EIM functionality.
Metrics That Matter
To avoid the legacy plateau, where planning is driven by inflated accuracy on easy cases and hidden exception costs, and to strengthen observability, ground your automation program in a concise, outcome-focused set of measurements. The metrics below tend to predict real-world success better than vendor-reported accuracy figures.
1. Useful Accuracy (across all documents)
Definition: Correct field or decision outputs divided by total items, including exceptions and edge cases.
Why it matters: Counters selective straight-through-processing-only claims and reflects true business quality.
2. Straight-Through Processing Rate
Definition: Cases completed with zero human intervention divided by total cases.
Why it matters: Measures actual autonomy and end-user impact in terms of speed and effort.
3. Time-to-Adapt
Definition: Elapsed time from a breaking change in UI, policy, or vendor to restored service levels and accuracy.
Why it matters: Captures agility and limits the cost of downtime.
4. Maintenance Load
Definition: Rules, templates, and models edited per month plus operational hours spent on upkeep, divided by total operational hours.
Why it matters: Serves as a direct proxy for the ongoing cost of ownership.
5. Resilience After Change
Definition: Post-change throughput in the first seven to fourteen days divided by baseline throughput.
Why it matters: Demonstrates how well automations endure real-world drift.
6. Trace and Lineage Completeness
Definition: Percentage of cases with a full record of perception, prediction, reasoning, and action, including inputs, versions, tool calls, and decisions.
Why it matters: Enables auditability, regulatory compliance, and faster root-cause analysis.
Conclusion
We opened this paper with a simple observation. Documents are everywhere, they carry most of the unstructured information that organizations rely on, and an estimated 70 to 80 percent of the documents that businesses would like to automate have remained beyond the reach of traditional approaches. That is where the operational cost lives, and that is the gap that each successive generation of document processing has tried to close.
The story we have traced is one of accumulation rather than replacement. OCR taught us how to turn pages into text. RPA taught us how to wire that text into business systems. IDP brought machine learning to bear on classification and extraction. Large language models brought genuine contextual understanding to unstructured content. Each generation did real work, and each generation reached a limit it could not cross alone. The honest reading is that none of them was wrong. Each was right about part of the problem.
Cognitive document processing is the first generation that reaches the long tail, and it does so precisely because it does not try to solve the problem with a single technology. Visual AI provides perception. Document geometry analysis turns perception into structure. Handwriting recognition and deep learning OCR turn pixels into text under difficult conditions. Vision-language model reasoning is applied deliberately, where judgment is genuinely required, rather than at every step. A confidence algorithm decides which documents proceed straight through and which are routed to highly productive human-in-the-loop review. The result is a system that is adaptive, transparent, and economical at enterprise scale.
Ecosystem information management is the logical next horizon: the same cognitive capabilities operating across organizational boundaries, with shared data fabrics, identity, and provenance. It will arrive unevenly, manifesting first in large enterprises and concentrated ecosystems before spreading more broadly. The pattern is the one we have seen before. New capability, real progress, structural limits, the next generation.
For most organizations today, the practical question is not whether to invest in document processing. The volume of documents and the cost of manual handling have already settled that. The question is which generations to invest in, in what combination, and how quickly. OCR, RPA, and IDP still do useful work. Large language models are powerful tools when applied with discipline. Cognitive document processing is what finally makes the long tail addressable. Understanding what each generation can and cannot do is the foundation for a document processing strategy that delivers on the promise the field has been making for thirty years.
We are, perhaps for the first time, in a position to take that promise seriously.
About Syncura
Syncura is an innovator in cognitive automation technology. Its platform combines visual AI with document geometry analysis, handwriting recognition, deep learning OCR, and vision-language model reasoning to deliver cognitive document processing and cognitive process automation solutions that adapt to real-world variability.
Syncura's products, the Cognitive Document Processor and Cognitive Process Automation, are designed to address the long tail of documents and processes that earlier generations could not reach. They support zero-shot processing, confidence-driven straight-through processing, and productive human-in-the-loop review, with audit trails and governance built into the architecture rather than added on after the fact.
For more information, visit www.syncura.ai or email